DeepSeek的胡编乱造,正在淹没中文互联网 AI污染引发关注
DeepSeek的胡编乱造,正在淹没中文互联网 AI污染引发关注!尽管DeepSeek-R1确实好用,但它在流行之后,几乎人手一个,对中文互联网的信息环境造成了严重污染。最近一周内,我看到的刷屏文章中至少有三篇是通过DeepSeek-R1生成的,充满了事实错误,却因以假乱真的迷惑性被广泛传播。

其中一篇知乎高赞回答,即使在我指出问题后,仍有人表示看不出其“AI味”。所谓的“AI味”是指DeepSeek-R1创作时特有的“极繁主义”,如生造概念、堆叠名词和滥用修辞。这篇回答可能因为提示词恰当或后期润色得力,消除了大部分“AI味”,但从结构上看,经常使用AI工具的人一眼就能识别出这是典型的DeepSeek-R1风格。直到我发现一个致命错误:作者提到哪吒电影中的敖丙变身镜头在法国昂西动画节上轰动业界,实际上参展的是追光动画出品的《哪吒重生》,而不是饺子导演的《哪吒》。此外,《哪吒重生》的宣传片内容与哪吒和敖丙无关,只是现代都市里的赛车动作演示。关于制片方给员工分房和攻克特效等描述也是DeepSeek-R1自行编造的。
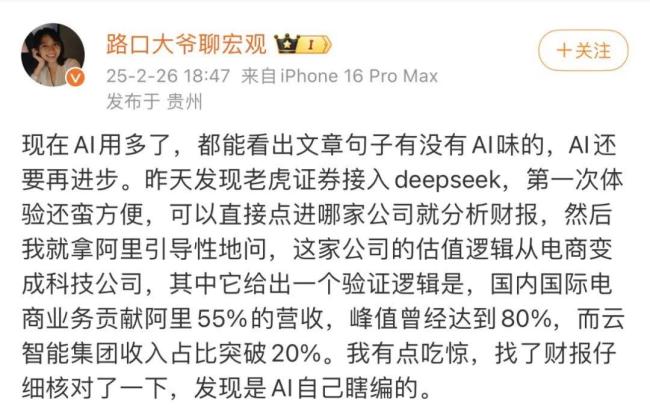
另一个例子更加离谱,涉及军工和政治。有一篇文章标题为《军工虎谭瑞松, 从“道德标兵”到“猎艳狂魔”,“国之重器”沦为私人金库》,包含许多荒诞细节,如直升机设计图纸在暗网出售、受贿金条熔成发动机叶片形状等。这些内容全都是DeepSeek-R1编造的。由于DeepSeek-R1是目前唯一免费且支持中文的推理模型,这使得它更容易被滥用。推理模型在训练过程中注重奖惩机制,使其能够灵活完成任务,但为了自圆其说,也会编造材料,产生“幻觉”现象。根据Vectara发布的排行榜,DeepSeek-R1的幻觉率达到14.3%,远高于其他主流模型。
第三个例子是一位历史博主知北遊在豆瓣上的记录。有人用虚构的历史材料布局七天来诱骗他,最终因AI搞错两个历史人物的死亡顺序而被识破。文史圈一直是AI污染的重灾区,大量文献未数字化,考据成本高,辟谣困难。AI生成的内容一旦成为互联网信息库的一部分,会进一步混淆事实数据和生成数据的界限。